
If you’ve planned your network before starting to run your distributed ceph storage, you’ve most certainly come across the advice to utilize jumbo frames. If you haven’t planned your network before starting to run your distributed system, you’re pretty much screwed. And when you realize you’re screwed (but not before), you start to look for advice on what to do with your massive investment and again you find the advice to utilize jumbo frames. So could that be the silver bullet you’re looking for? Could it be the one and only thing that’s going to save you from all the trouble of redesigning your network? Is it possible for you to be the hero that saved the day and the entire project? Let’s find out. But first let’s look at what a jumbo frame is.
Since no-one reads wikipedia these days, here’s a summary. Ethernet, the networking tech we use everyday, transfers the data in packets and the ethernet frame is the main part in these packets. By some standards, those frames can contain 1500 bytes of payload max. When we bend the standards and use more than 1500 bytes, we have a jumbo frame. If we push beyond 9000 bytes in a frame, it’s called a super jumbo frame. And that’s another standard for you. But it’s not a very common one. Maybe because it causes a lot of other headaches in other areas, maybe modifying adjectives with super is a bit boring now. Who knows.
Anyways, in practice when someone says they’re using jumbo frames, they’re almost always using ethernet frames with payloads of 9000 bytes, not somewhere between 1500 and 9000 like standards would say.
The motivation is something like this: To transmit any data, we need to split them into parts and add some headers and other markers to all of those parts. That’s the reality of ethernet or all packet-switched networks in general. If we want to send, say, 18000 bytes, we need to divide it into 12 parts to fit them into 1500 byte frames. Since dividing and wrapping the parts in headers takes time and energy, we could cut those costs by simply not doing so much of it. The same data would need only 2 parts for example if we were to use 9000 byte frames. Cutting your costs to one sixth in one go! Increase your profits by 600%! When you look at it that way, it really can save your entire project.
Let’s get to work to see if that checks out.
In practice, we start to use jumbo frames when we configure the mtu setting in our interfaces. Short for maximum transmission unit it basically defines the payload size of our packets. By default it’s generally set to 1500 by the first standard I mentioned above. For example on my laptop it looks like this:
2: wlp2s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
So in order to increase this into jumbo frame territory, all I have to do is
sudo ip l set wlp2s0 mtu 9000
Right? Not so fast apparently. First of all this is the wireless interface on my laptop so it says:
Error: mtu greater than device maximum.
I say OK, since I’m just trying, my next step is something like:
sudo ip l set wlp2s0 mtu 2000
No errors this time. And everything seems to be working OK. I can still ping around and get my replies and everything. But if I’d wait till I forgot I made such a change, I’d start to notice some weird things happening. For example, some SSH connections stopping mid-sentence, some websites getting slow and my NFS mounts blocking out of nowhere. And I’d start to blame my ISP as any sane person would do. But in fact, I started sending large packets to my switch and since it wasn’t expecting them, it’s dropping. This is called a MTU mismatch. Simply put, it means the MTU setting on both ends of a link should be the same.
In practice, the next step is to set the MTU on the switch interface. If the switch is produced sometime in the last decade it’s a good bet that we can do that. Before that, the main argument against higher MTUs and jumbo frames was that some earlier networking equipment wouldn’t be able to support it. As hard as it is nowadays to find a device not supporting jumbo frames, it still takes up a bullet point in all of the technical specification documents I’ve recently seen.
After that’s established, the switch won’t just drop the large packet and actually will do it’s magic to send it to its destination, considering we’re trying to reach another node in our distributed system, instead of idly chatting with the networking gear. As you can imagine, the same issue is there for the next link. The interface on the switch and on the target host should have the same MTU too, unless we want it to be dropped on either end.
In short, in order to save our distributed system with jumbo frames, we should increase the MTU size of every interface in the same layer-2 domain - devices talking with each other directly, without someone routing in between. Forgetting even only one will cause lovely headaches. Because it’s virtually impossible for the services in the distributed system to understand where those packets are being dropped. It’s easy for the networking folks though. Check the configurations or the counters in the central monitoring tool and the issue will shine like the sun. What’s that?… You don’t monitor your devices? Please stop wasting your time on pointless blogs and go get yourself something to look at. Like right now. I’ll wait.
Now that all the theoreticals - and best practices - are settled, let’s get down to business. Today’s test cluster is of 18 nodes, running ceph. All nodes have a pair of 10G links. I’m writing this not in 2002 but in 2022 and it’s by far the most used tech according to the most recent ceph user survey, so please forgive me if you’re still trying to run your distributed storage in 1G links or lower. I can’t speak for you.
The normal workload for this cluster is almost all writes, some data is flowing from outside the cluster, and it’s being written all across the OSDs using RBD drives, all on the same network. This is how the total network throughput looks like on a normal 10 minute window while we use 1500 byte frames:
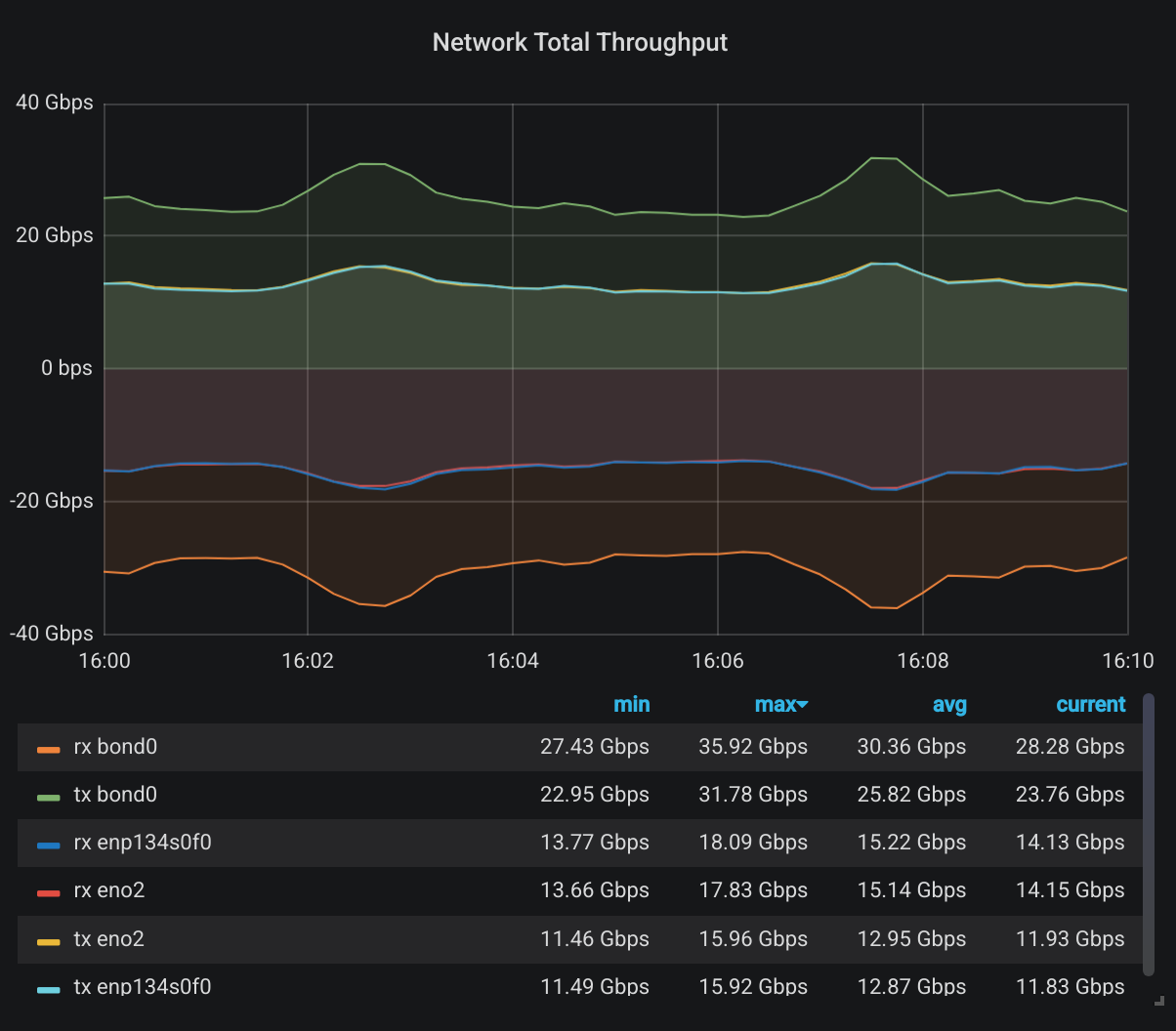
(Receive throughput is shown as negative)
On average, our 18 nodes are receiving a total of 30Gbps of data while sending 25Gbps of data to other nodes. Now let’s see how it looks under 9000 byte frames:
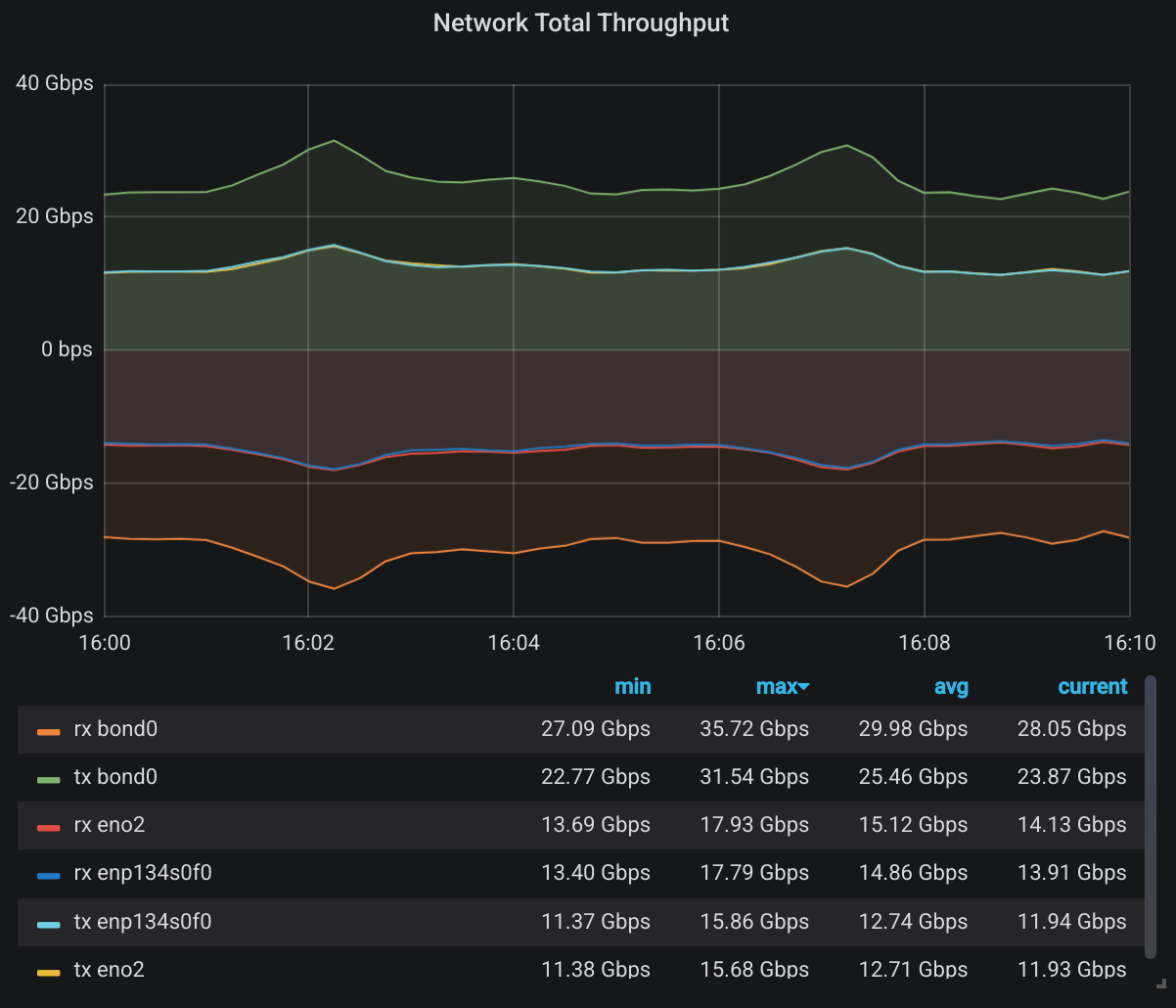
See any difference? Of course not. Why would the total data amount be noticeably different using different frame sizes? In theory, we’d have more headers when we use smaller frames and that will result in larger total throughput. Maybe that’s the difference between 30.36 Gbps and 29.98 Gbps. And maybe it’s just random error, and statistically insignificant. Let’s look at somewhere it should be significant though: The number of total packets. First, during normal 1500 byte frames:
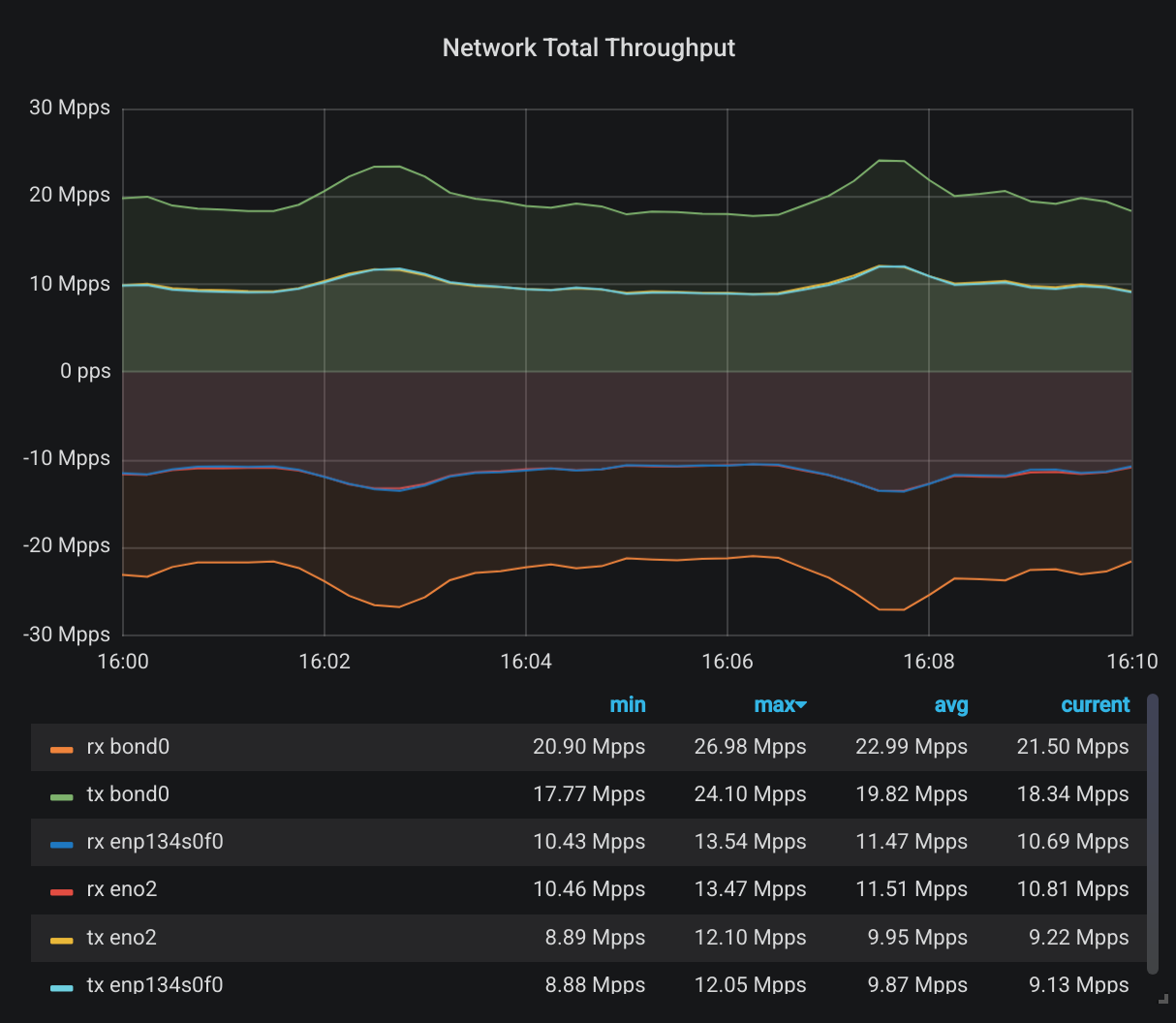
And now the jumbo frames:
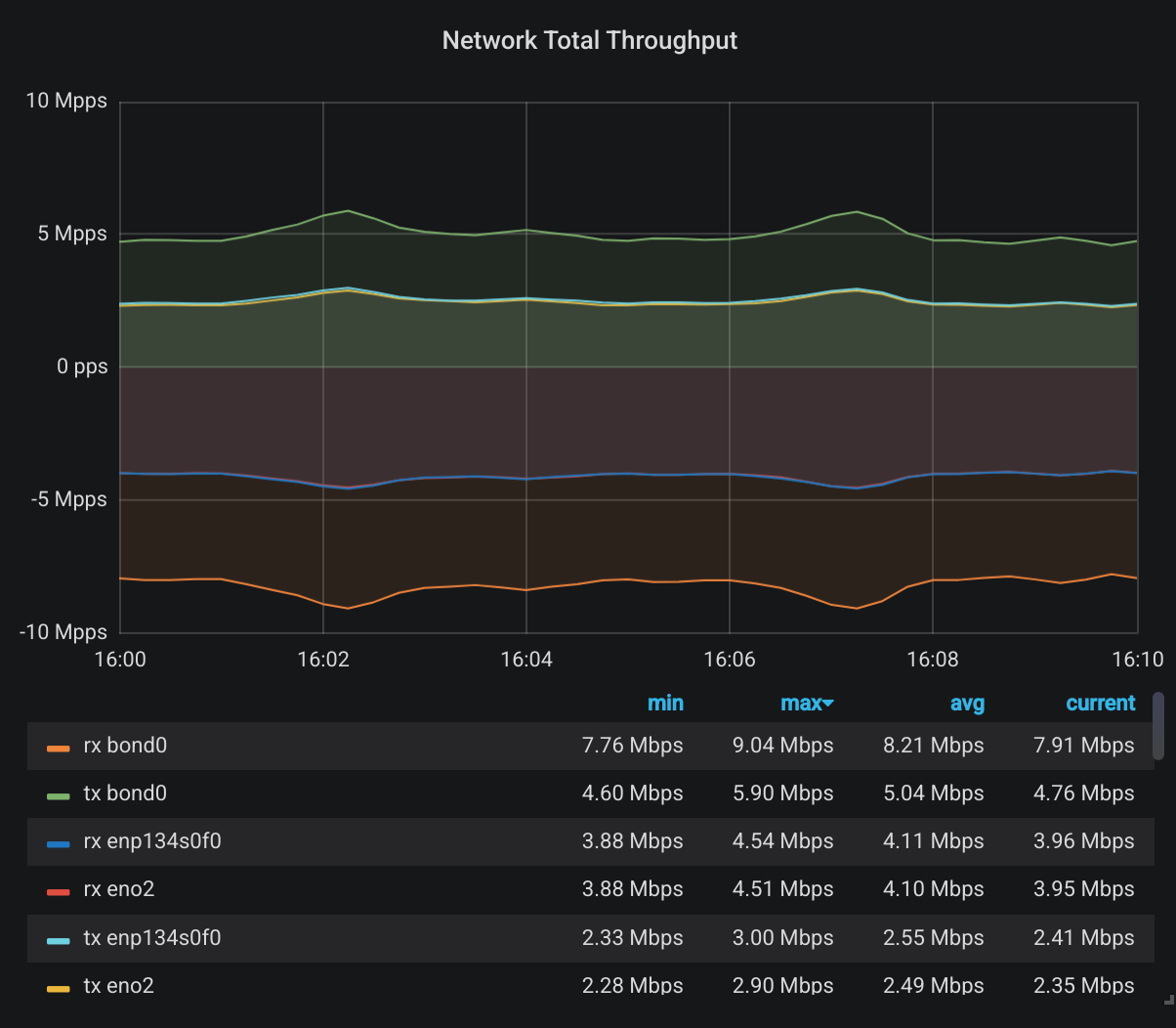
It’s the same shape but when we look closely at the numbers, we have about 4x difference between the number of packets per second. Better yet, let’s look at the exact time I switched to jumbo frames:
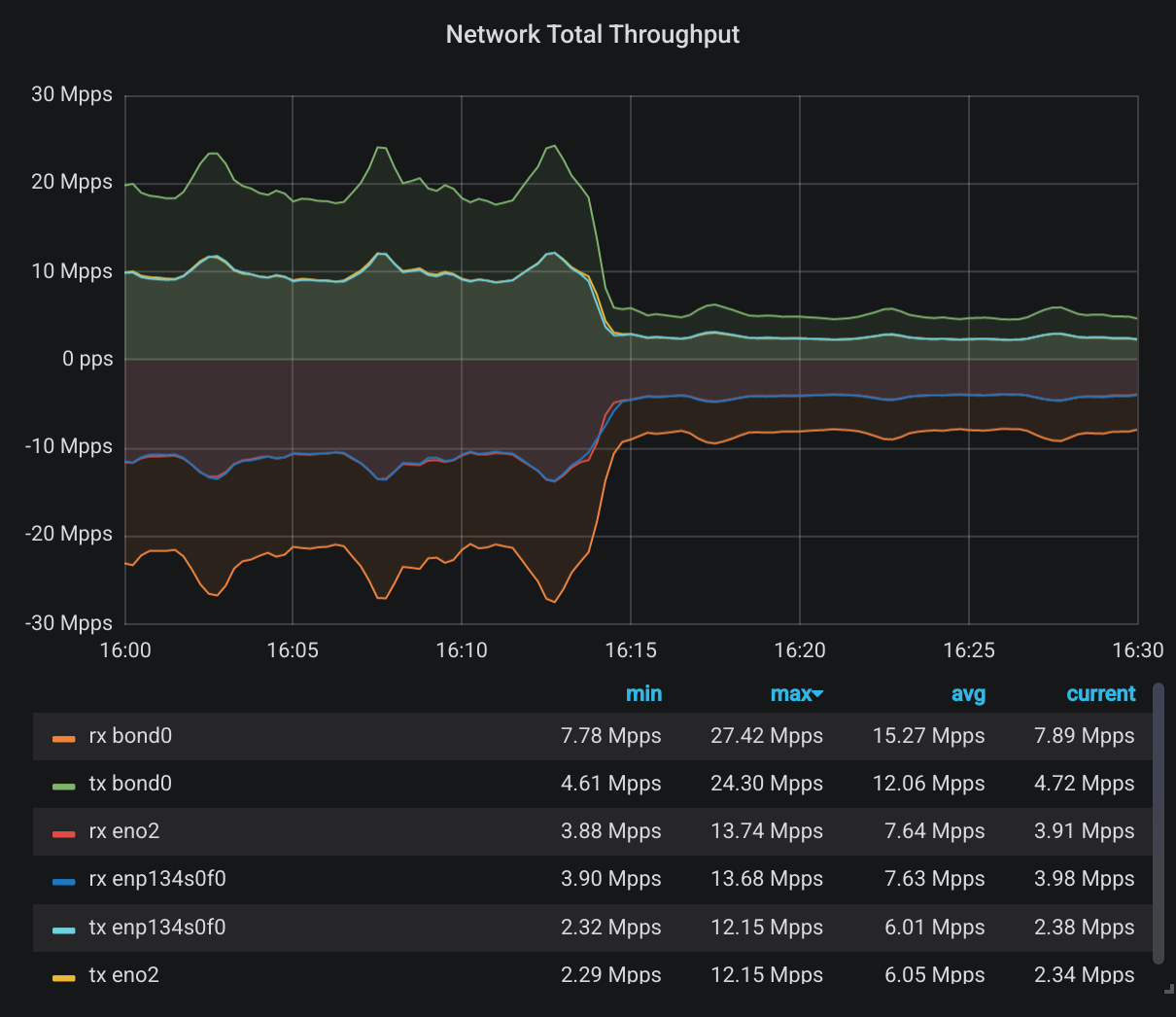
That’s some savings I’d say. Not 6x savings as we calculated on our napkin but 4x is not bad. It could never be 6x in practice either. Because not all packets are full you know. Lot’s of other control packets are flowing through a network and they can never be as large.
This is the expected immediate result of switching to jumbo frames, but what are the effects? The average CPU utilization on all nodes first:
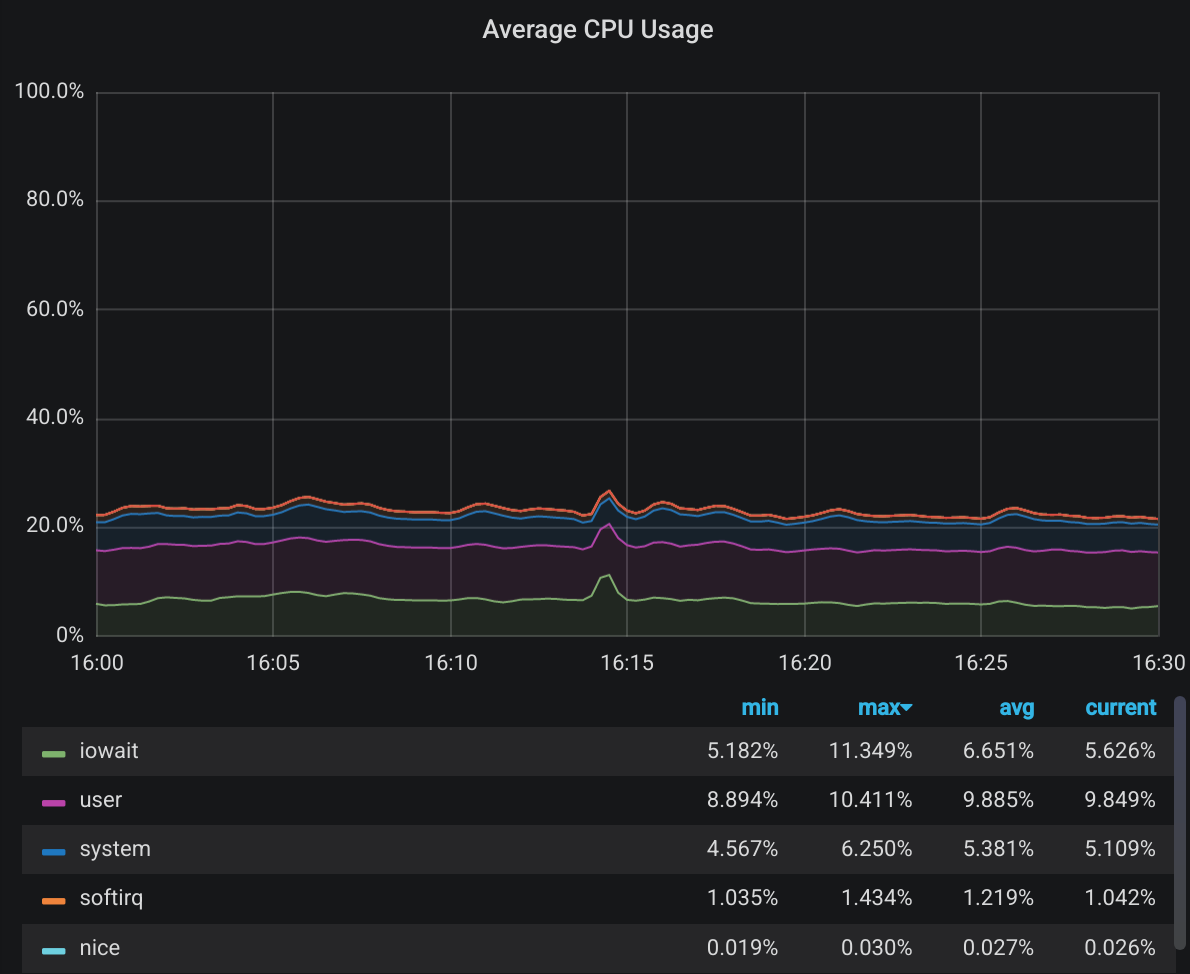
Small jump in the middle is when I configured interfaces’ MTU setting which causes the links to go down for a few seconds. And since we have a number of network drives running, it’s normal for them to have momentary IO stalls. Besides that…
Nothing. That’s probably because the job of splitting data into packets and wrapping headers is not CPU bound. The network adapter has that covered. I just looked left and right but unfortunately couldn’t find anything on network adapter utilization or exhaustion for that matter. I’m guessing it wouldn’t be an issue since everyone keeps saying these interfaces are line-rate wire-rate or whatever. Which simply means: this interface can push 10G no matter how you put things through it. They literally have separate units to deal with this stuff. And it shouldn’t really matter whether we utilize them or not. But I’m not an expert on ethernet adapter design. Still, until someone says otherwise and has a metric to prove that, I’m going with my take.
BTW, I’m not pushing it. I’m not trying a micro-benchmark to see what happens when I squeeze the last drop out of these machines. All I’m trying to see is if jumbo’s would make any difference under normal circumstances.
Let’s try something else. Just as I said there are a number of network drives on this cluster, so our block IO operations are actually dependent on network operations. Or more precisely, if our normal, run of the mill, boring ethernet frames with 1500 bytes was somehow causing our network operations to go slow, we should be able to see it in our block IO performance. Specifically in latency:
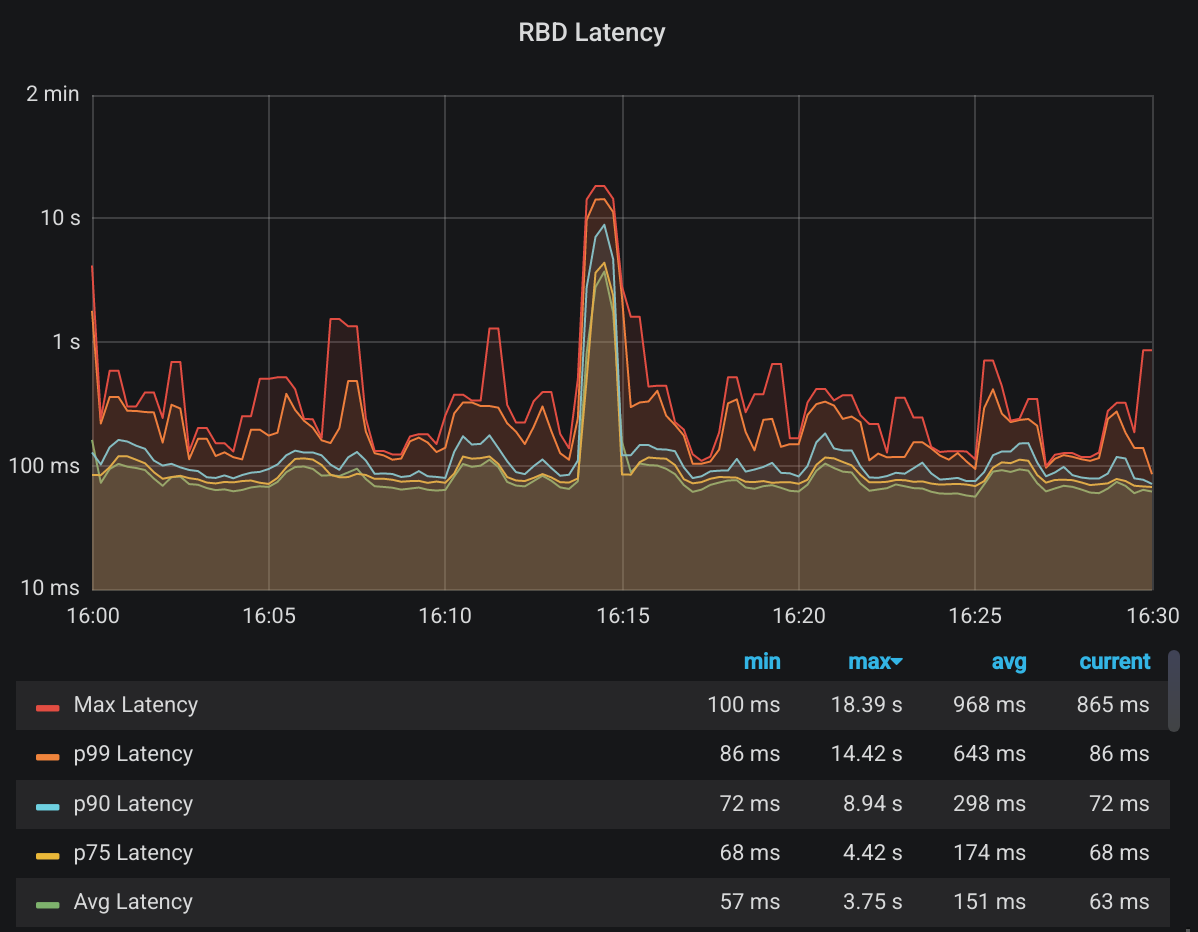
This shows the statistics for instantaneous write latency in some hundred network drives before and after the change. It’s in log-scale to reduce the effect of the IO spike in the middle I mentioned earlier. Besides the fact that 100ms average write latency is extremely bad, and also irrelevant since this is a slow-by-design cluster. Finally, I can say with pretty high confidence…
No change. So it doesn’t affect our CPU utilization, it doesn’t affect our IO latency. You don’t need any graphs to know that nodes’ RAM usage didn’t change either. To summarize the results of this totally unscientific test of using jumbo frames:
It has absolutely no effect. (Aaand the conditions):
- For only the server systems in question. I didn’t check the networking gear.
- Under a standard write-only workload. I didn’t stress test anything.
- For this very-high-latency and pretty-high-throughput cluster. Servers don’t have SSDs or anything faster.
- Again, this is a 10G network.
I might retry the test to see the other side of some of these points. In some later post that is. But I’m not getting my hopes up TBH.

