Blog

Bitter sweet data compression with ceph
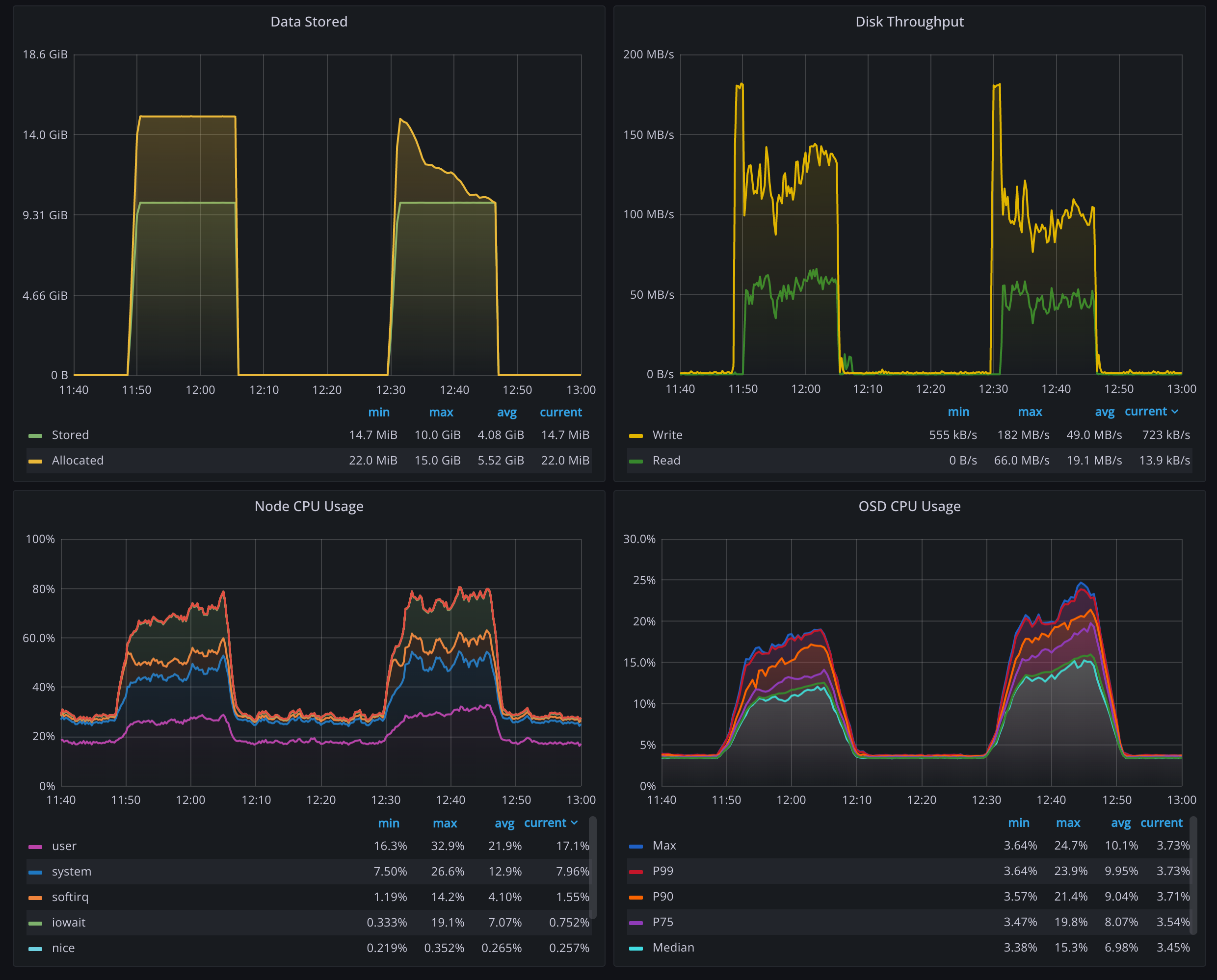
Almost all data storage solutions have some sort of compression capability. It’s being told as a killer feature from time to time, reducing storage costs substantially, even moving some projects into feasible realms. In our experience though, the data was always compressed beforehand. Because, compressing was and is always the obvious first step, not only before storing the data, but also before moving it around, sending it to the first client, etc.
Nov 1, 2022

Exploring the effects of jumbo frames
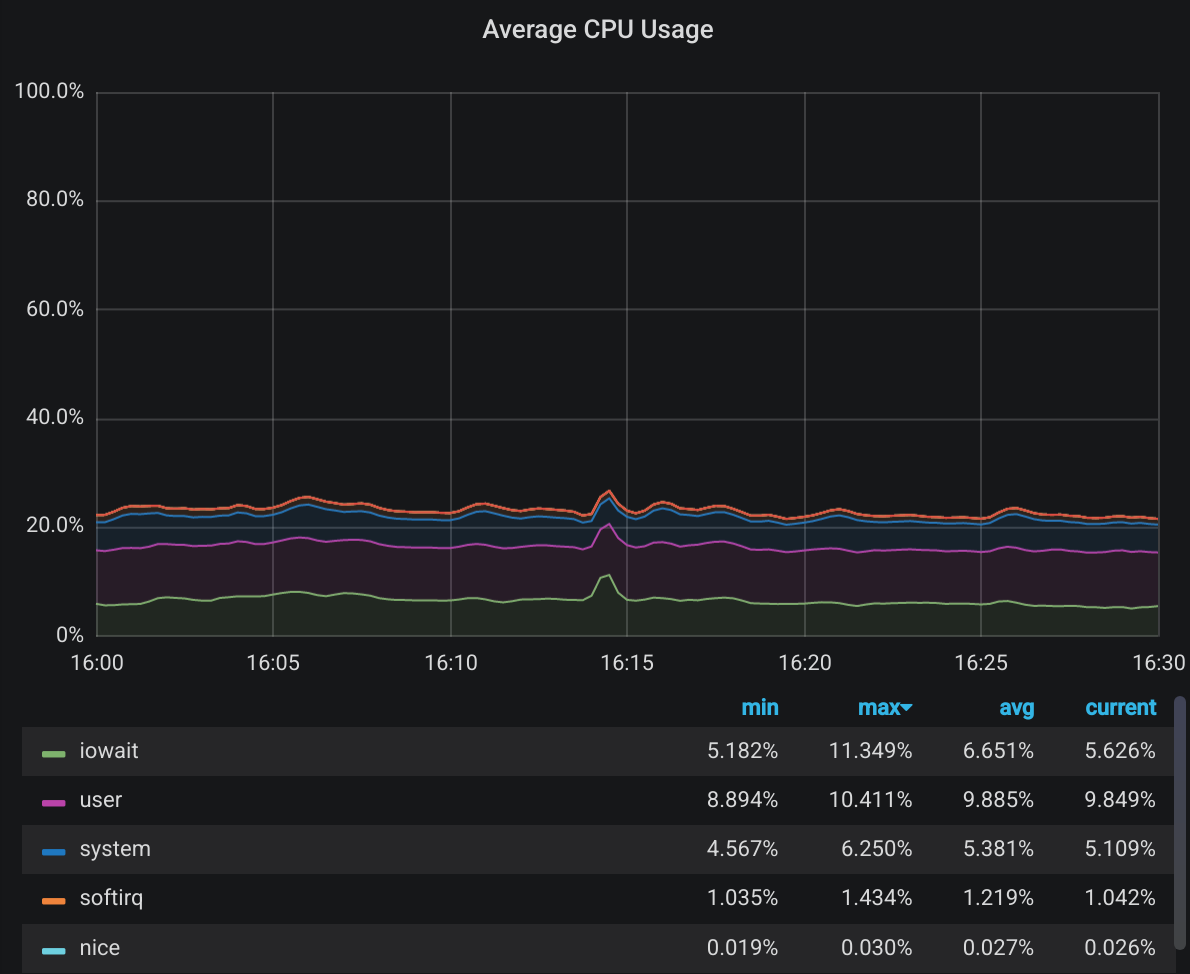
If you’ve planned your network before starting to run your distributed ceph storage, you’ve most certainly come across the advice to utilize jumbo frames. If you haven’t planned your network before starting to run your distributed system, you’re pretty much screwed. And when you realize you’re screwed (but not before), you start to look for advice on what to do with your massive investment and again you find the advice to utilize jumbo frames.
Feb 18, 2022
Costs and benefits of erasure coding - In style
In the last post we left our discussion where we somehow needed to improve the recovery performance in our largish cluster but we didn’t really know what to expect or improve. So in this post we evaluate some alternatives and run some tests to see what happens when we lose a drive. But first we start by reading through the docs a bit.
Aug 9, 2021
Costs and benefits of erasure coding - In numbers
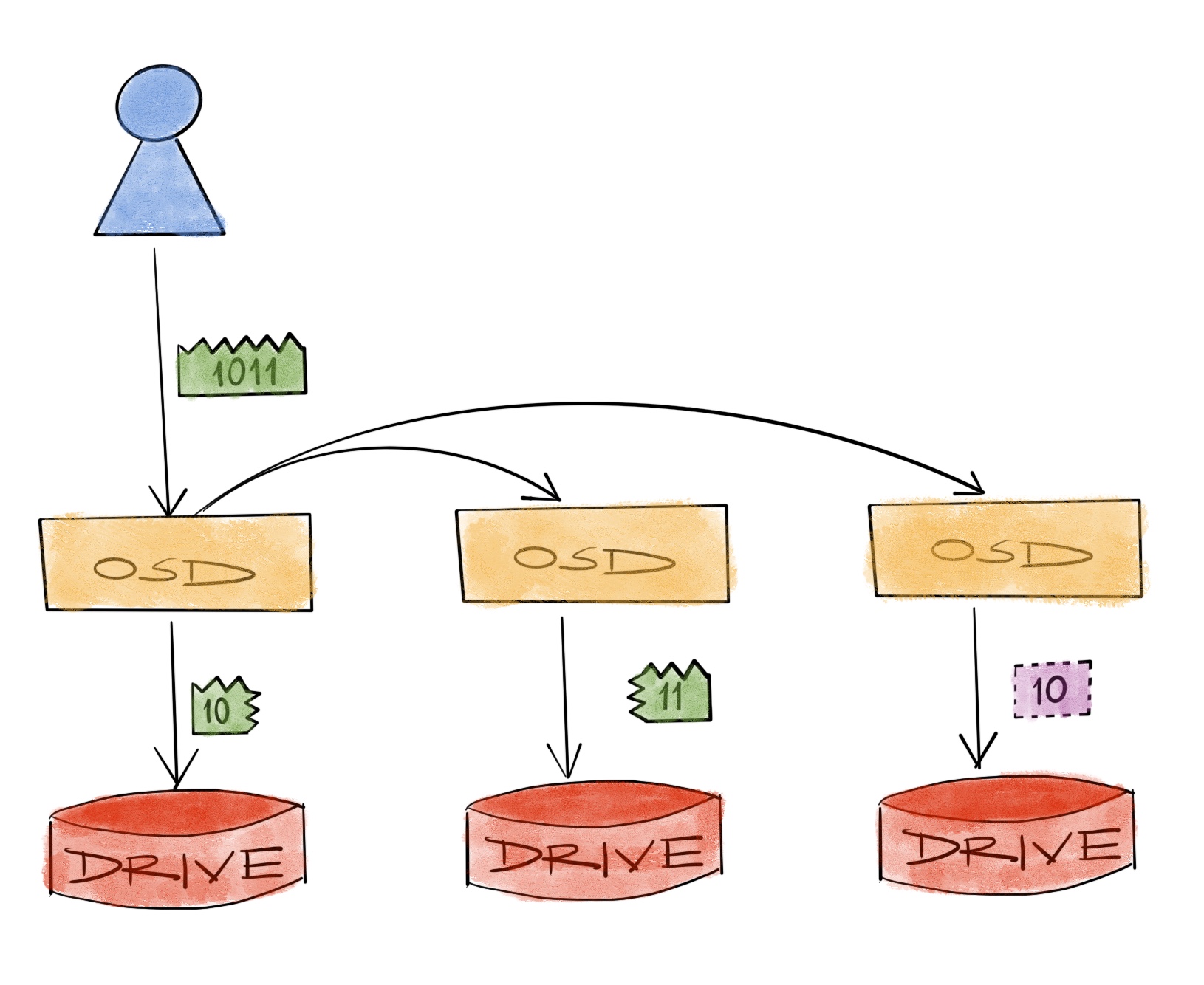
Last time we talked about different levels of complexity and why engineers complicate things they complicate. And the short answer was: it’s easier that way. Not because they love to complicate things, or to prove that they can work complex things better than everyone else, but because it’s easier. It’s easier to complicate large and costly problems to make them cheaper, than trying to find massive amounts of funding needed to solve them in a simpler way. Simple is expensive.
Aug 2, 2021
Using gRPC for flow-control between .NET and Java
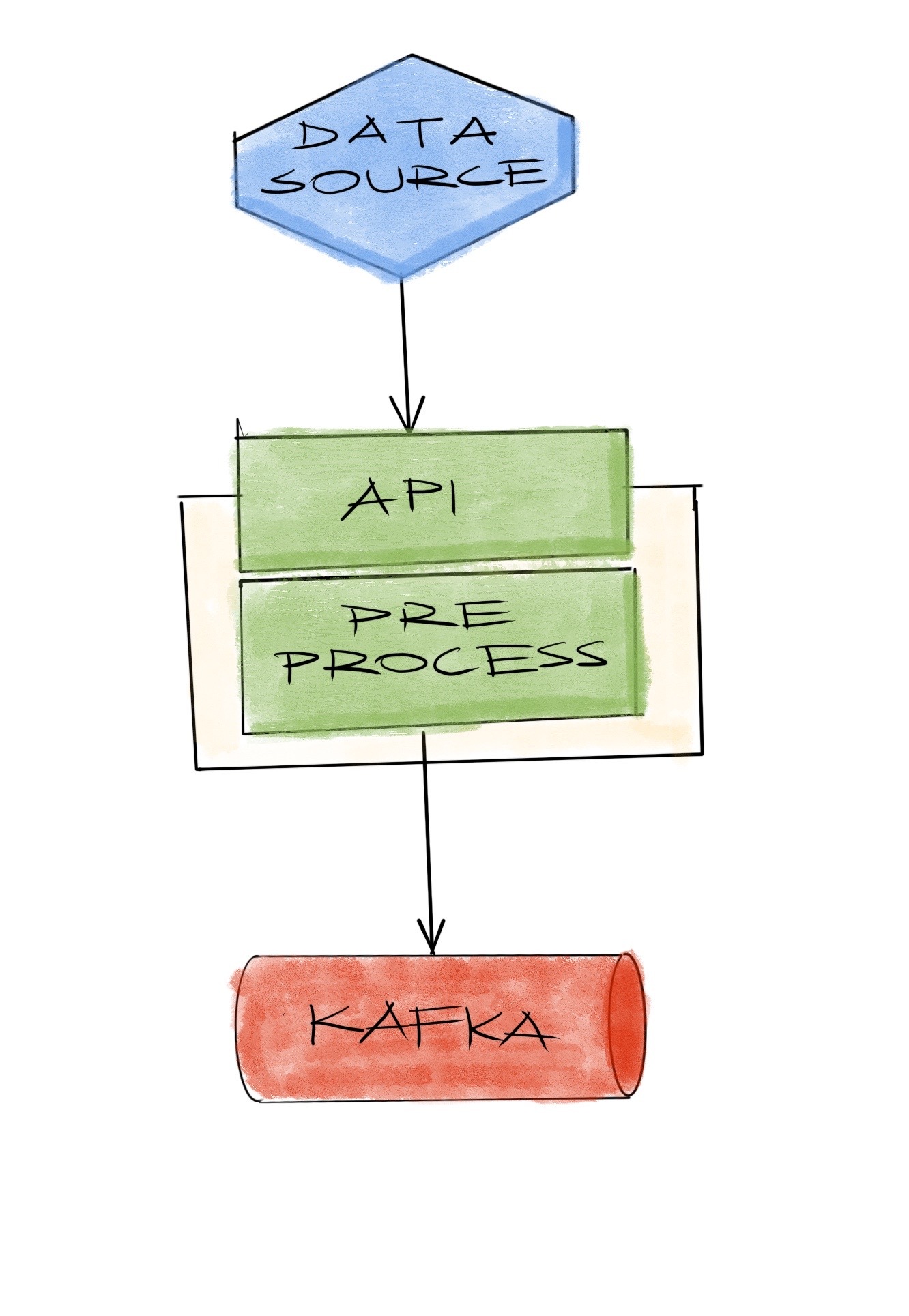
Call it data science, big data, data engineering, or just a plain SQL database, one of the constant things is that all need a way to ingest the data. Without the data itself, none of the differences between those concepts matter much. Another constant is that the systems we rely on will fail at some point. In this post we focus on how we try to design the structure for a streaming data project where we could receive data somewhat reliably.
Jul 23, 2021
Costs and benefits of erasure coding
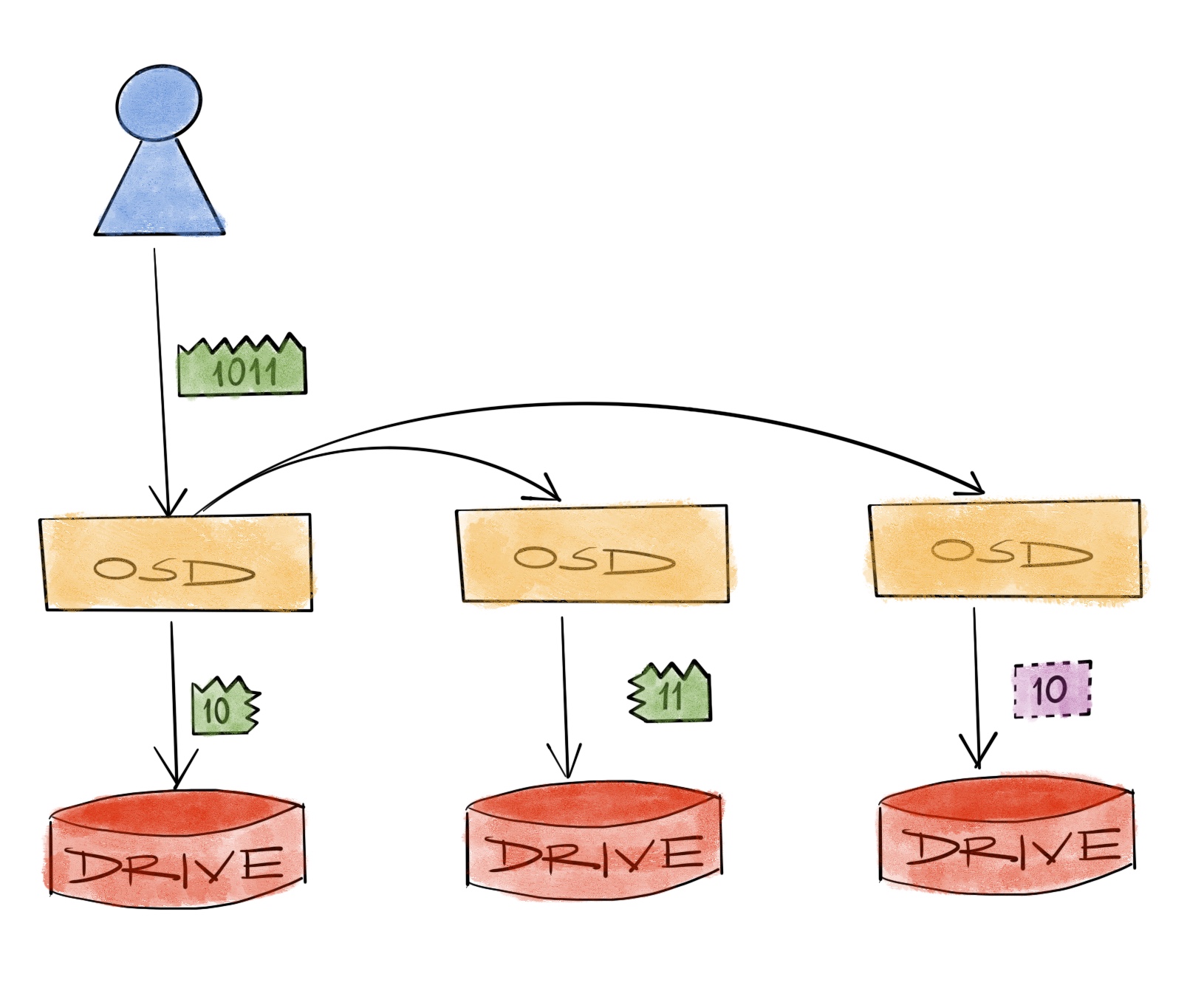
Durability is what separates a data storage system from simply using an external hard drive, a USB stick or a smartphone. When one of those simpler storage solutions fails, it’s safe to say that the data is toast. When we don’t want the data to be toast when things drop out of our pockets, we back them up to a more secure place like “the cloud”. We do that because we cannot reliably stop things falling out of our pockets no matter what we do.
Jun 6, 2021
Configuring gRPC retries
I never understood the difference between the service oriented architecture and the micro services really. Yeah SOAP is archaic now and JSON saved us all, but in fact, they all look like applications making requests and expecting responses over the network. And similarities don’t end there. Like what to do when the application, a) doesn’t receive a response, or b) receives a response it doesn’t expect.
Apr 15, 2021
Large scale hardware testing
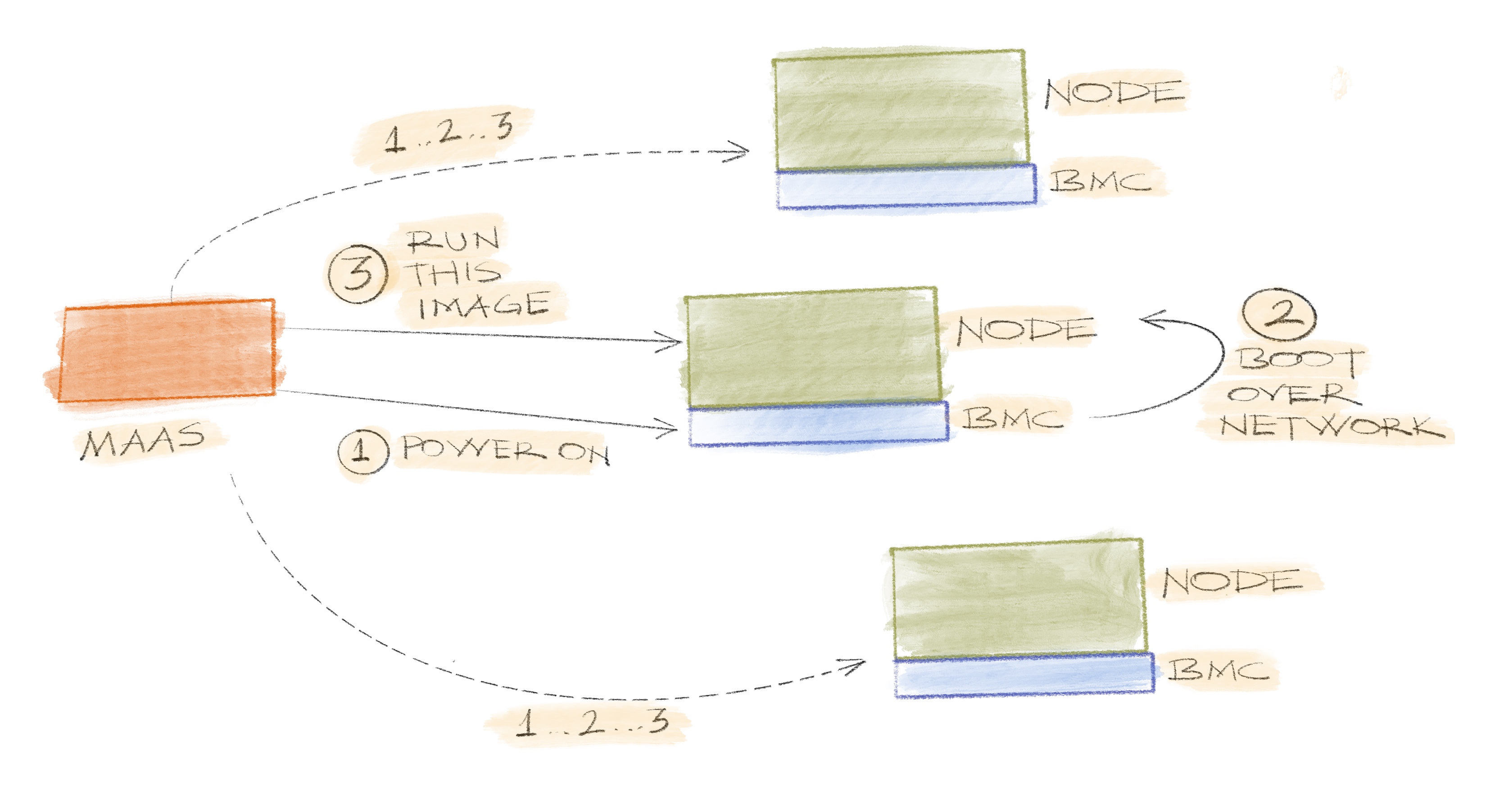
We all have a few servers in our offices, or a colocation provider or in a part of a data center. And a few more every year is not much of a problem. Unpack, deploy, plug, install, reboot and that’s it. Still a few more steps than what you’d need in a cloud environment but nothing an experienced technician can’t handle. Things change when numbers are around some hundreds though.
Feb 26, 2021
Distributed ceph monitoring
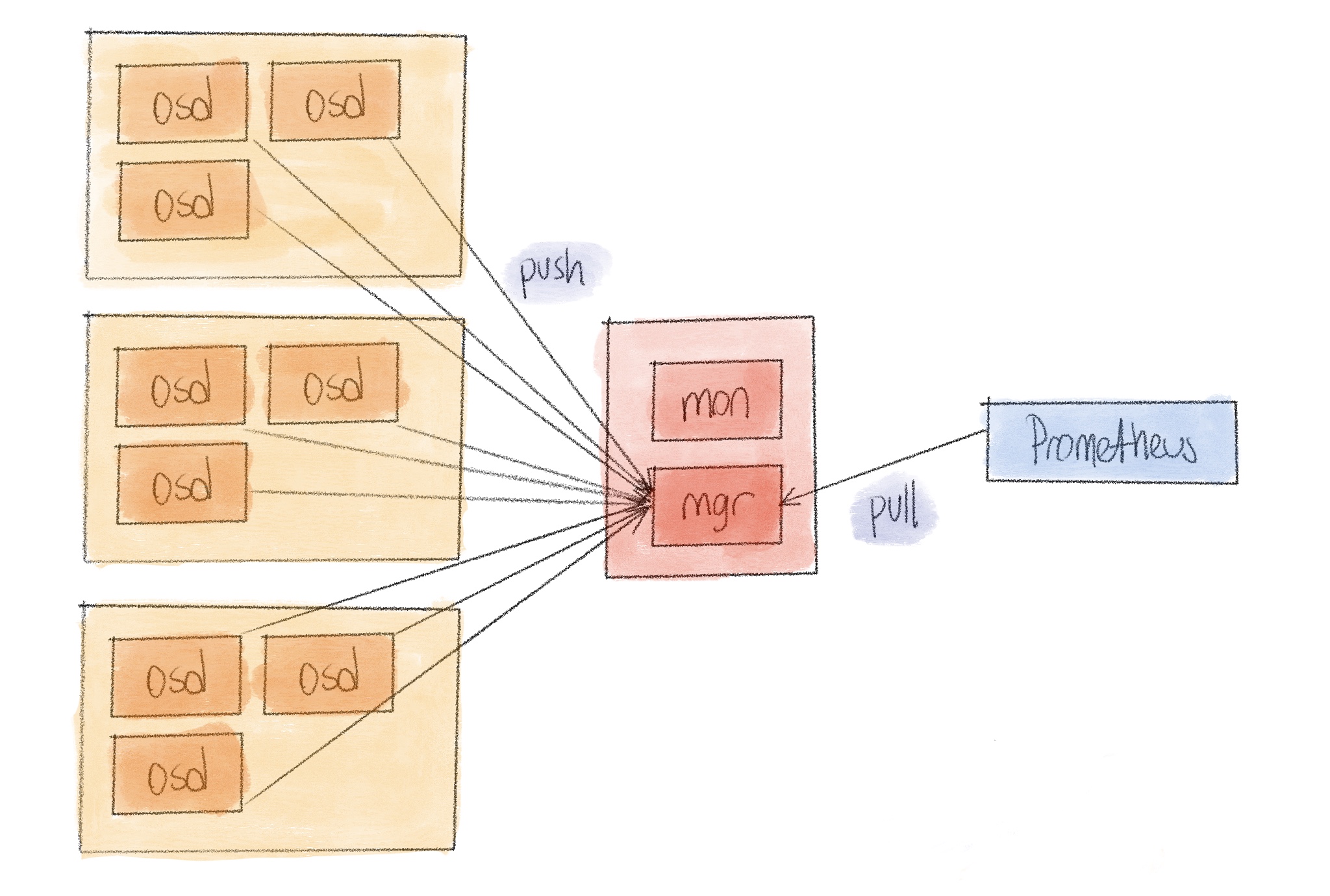
Like any distributed system, reliability of ceph operations largely depends on the available monitoring. Over the years we have seen and deployed many solutions ranging from zabbix to opentsdb to others for the same purpose. Nowadays our general choice is around Prometheus and that goes for ceph monitoring as well.
Dec 24, 2020
A login page with vuex and vuetify
In the early stages of one of our newer projects, we implemented the login
screen and the required isAuthenticated control by using local storage
directly. Since then we adopted vuetify and had to
redo the screen so why not take this opportunity to learn something new in the
process. Enter vuex.
Nov 30, 2020

