
We all have a service that we run with multiple instances of the same application, to keep it available even when one of them goes down. When we do that, we usually deploy a reverse proxy (or a load balancer) to direct the users of this service to the instances.
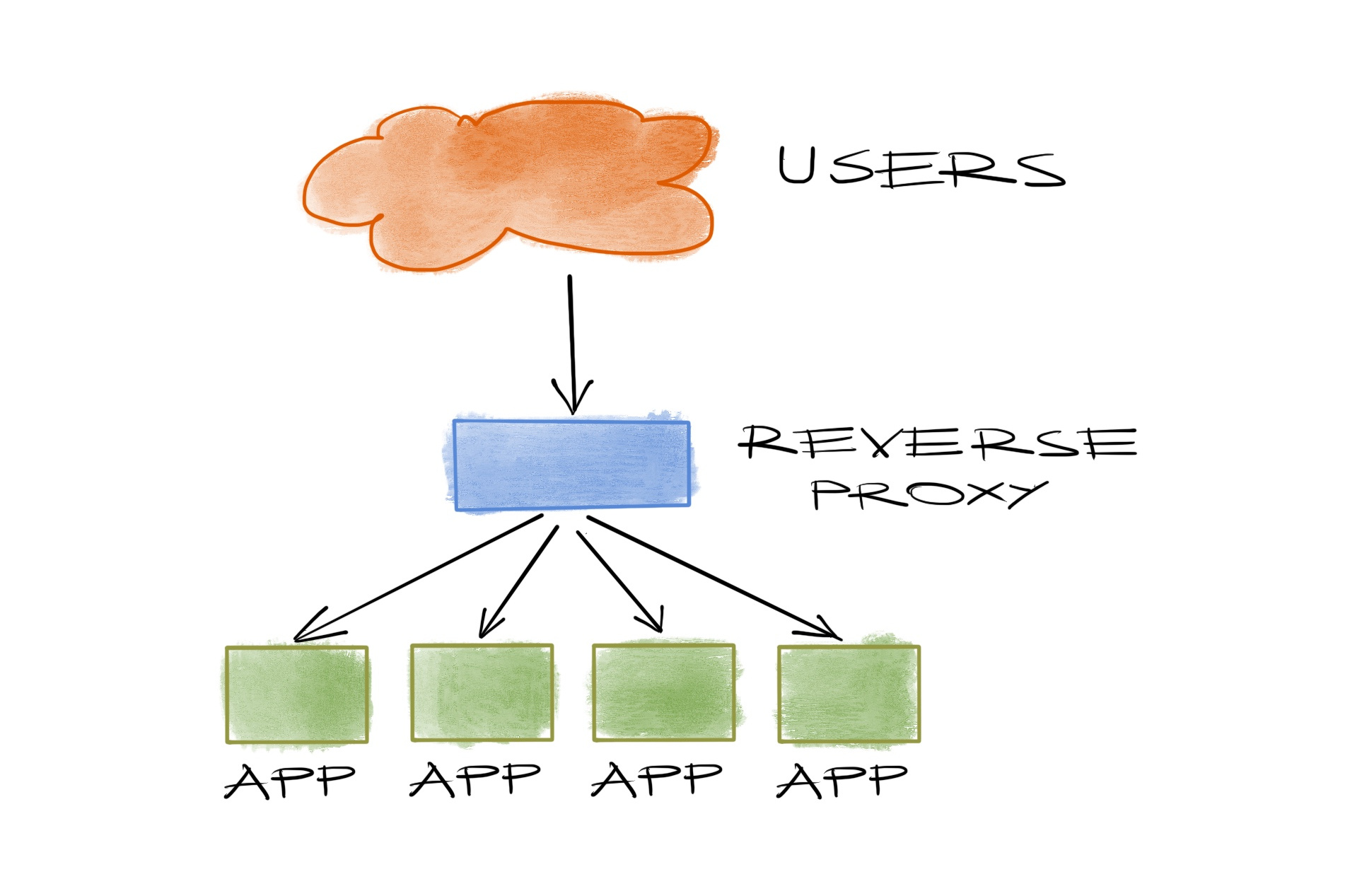
That’s one of the reasons tools like haproxy and nginx gained huge popularity in the last decade. They usually check the instances periodically to use the healthy ones only. But they leave out a final detail: who’s going to ensure availability when they go down?
An ELB in AWS or something similar in others, that’s who! If you’re in a public cloud of course. If not, you have “a lot” of options to choose from:
- Deploy a hardware load balancer, and worry about its availability
- Add all of your reverse proxies in your DNS record and hope your clients will try the healthy ones
- Use BGP, ECMP or anycast IPs if you’re sure you have the right networking equipment
- Run keepalived on your reverse proxies to failover your service IP to another one
Last one is an easy solution especially if your environment is allergic to DNS, or your service is the DNS itself, so your clients will try to access a specific IP address no matter what you do.
Keepalived to the rescue?
Keepalived is an application which can ensure an IP address will always be online on a set of servers. It sets one of them as the master and others as backups and when the master fails, a backup will take its place and have your IP address.
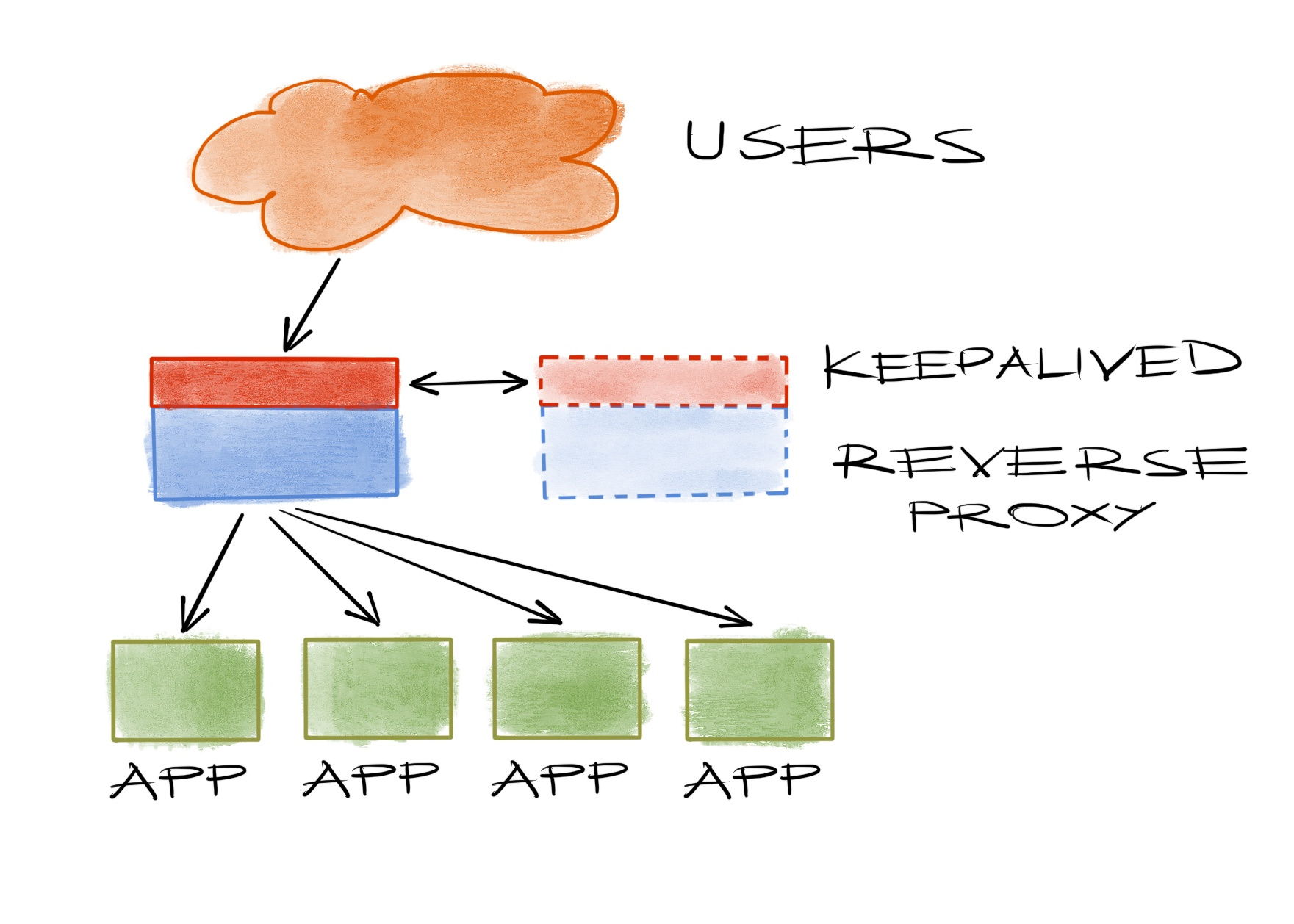
So the clients will reach this new server instead of trying the failed one and, … voila! availability. You can find thousands of articles around the web showing you how easy it actually is to have a basic setup.
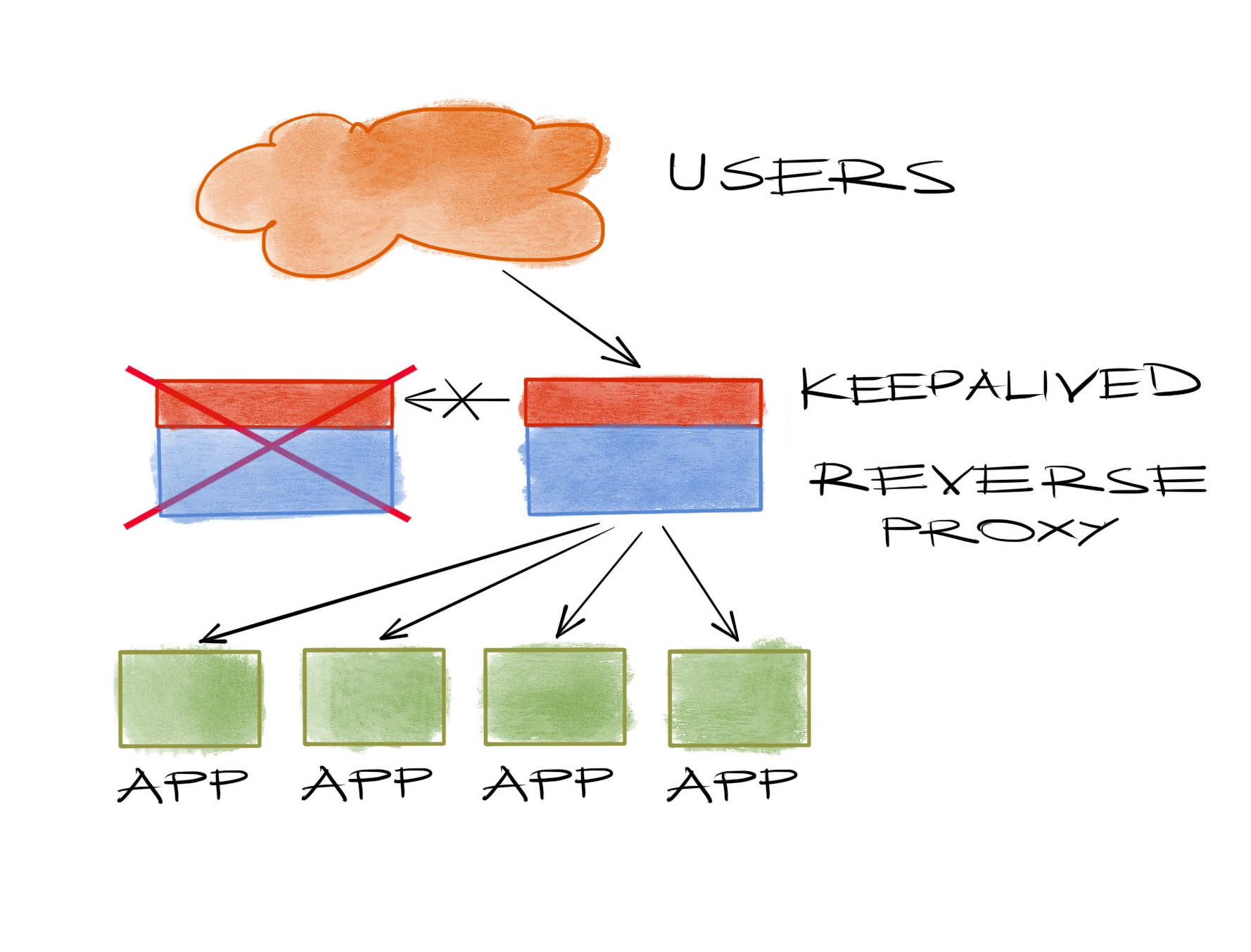
So why wouldn’t you want to use keepalived? Why go for an alternative? Especially considering everyone uses it to the extent of writing thousands of articles, encouraging everyone else to do the same?
First reason would be that keepalived, by default, relies on multicast, and you can’t have it, as in AWS VPCs, or hate its guts, for some personal reason. But that’s ok because keepalived can work with unicast instead for some years now.
Another reason would be the reality that most machine failing scenarios are not clean power downs as you’d like to believe and you’d likely to have tested against in the early days of your deployment, but they’re messy things like intermittent packet drops, arp table overflows, oomkillers or some other rare BS that happens after 2am in a Sunday morning, and keepalived backups are just too eager to become masters that they do it at the first chance they have, to add an IP address collision mess to whatever you have to be dealing with in the first place. In short: a nasty split brain.
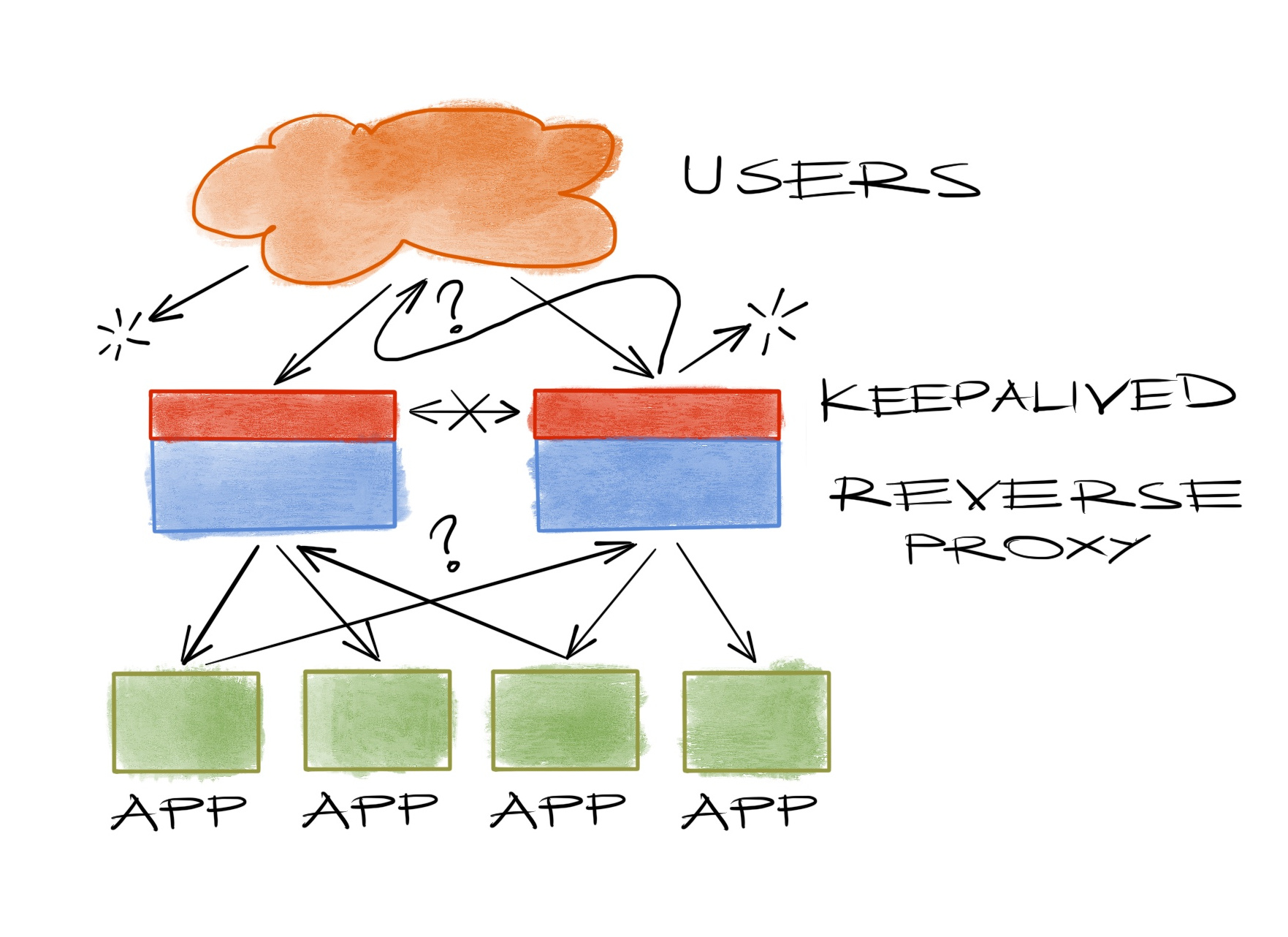
Realities of networking
While this seems a bit exaggerated, it is in fact a well known problem in computer science. You can’t just ping a server and say it’s down. Well, maybe you can, but don’t trust your servers to do the same automatically. It’s not that easy for a piece of machine to decide on who’s really failing in a distributed environment. Yet every distributed application requires that decision at some point. Which is why Google has chubby, Hadoop has zookeeper, kubernetes has etcd or you might have consul. Nowadays, everyone uses a system utilizing a distributed consensus algorithm to form a safe master-backup relationship in the face of failures. Except keepalived.
While it might be a bit overkill for a small environment to run a consul cluster just to have a single IP address available and you might be just fine with simple pings anyway, but if you need to deploy something similar for one reason or another, I say use it!
Keeping kubernetes alive
Today’s example is a kubernetes cluster. Kubernetes will deploy load balancers for the services on the fly and configure ingresses automatically and do lots of crazy stuff within the cluster but it cannot do that for its own main service. Apiserver is the core interface to the cluster from inside (the nodes) as well as from outside (users) and while it’s possible to run it with a number of instances, someone else has to direct the requests to them.
Somewhere early in a kubernetes deployment procedure, the authors will remind you of that fact and point you in the direction of ELBs, again. And if you’re deploying outside a cloud, something on-premise, something bare metal, you’ll have “a lot” of options, again. But you’ll have an etcd cluster up and running by then. So I say, use it, instead of another logic trying to do the same.
A fresh solution
That’s why we developed govip. It does the same thing as keepalived while setting the IP address (a VIP in similar terms), but instead of trying to check the health of others, it will use an etcd cluster and try to become the leader in an election first. If it wins, it’ll put the VIP on the specified interface. Etcd will ensure only one of the govips can be the leader at any given time using the popular raft algorithm. If it can’t do that, like when the etcd is somehow down, it doesn’t matter anyway because that means your cluster is already broken. It’s always good to have fewer things to worry about.
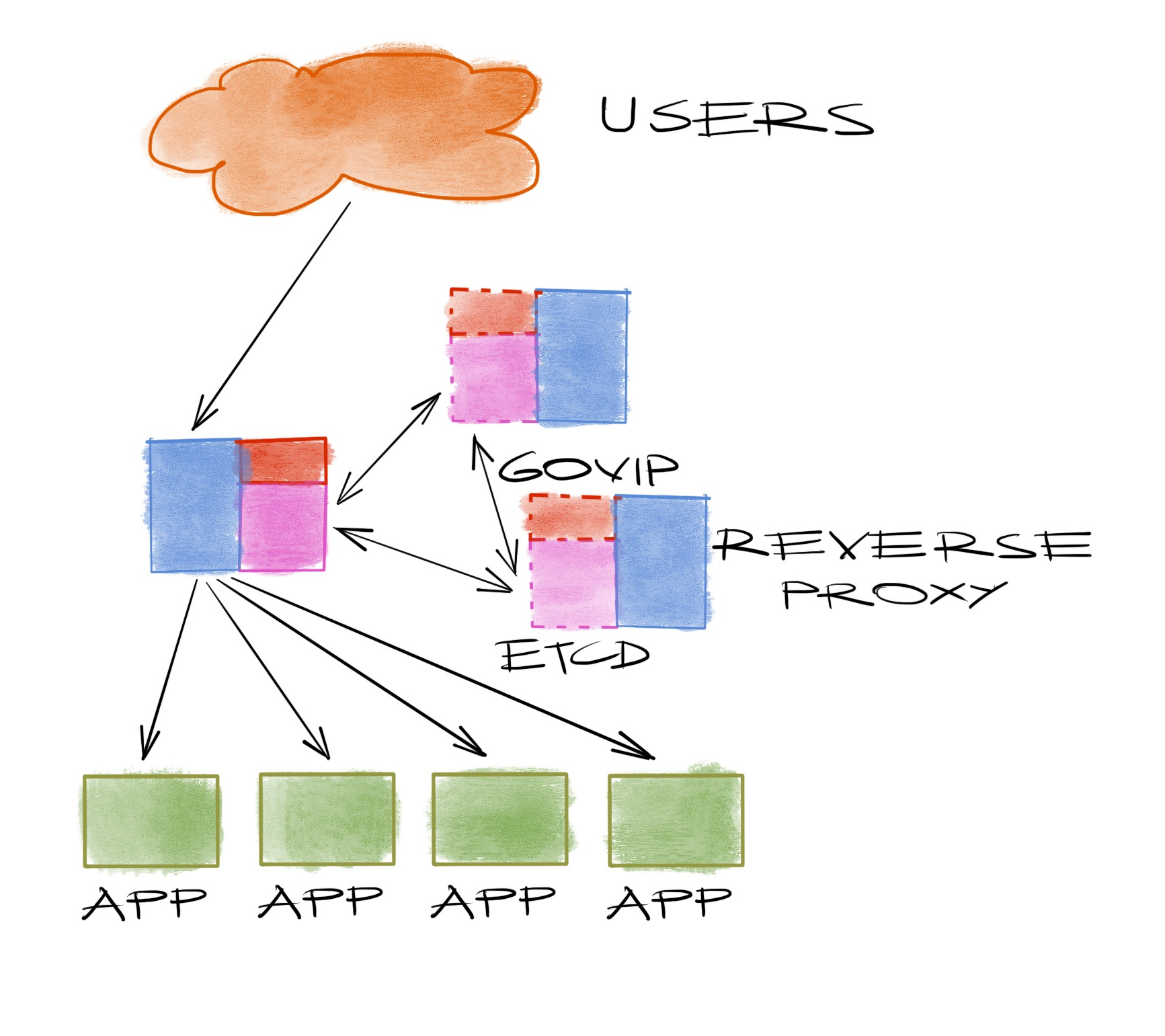
Back to today’s example, we deploy govip where we can receive requests for apiservers. That’s usually where the apiservers are, but that’s not necessarily a good idea. Govips don’t check the health of the service so it’s possible to set the IP on a node who’s supposed to be running the apiserver but doesn’t. And when the apiserver is running, it’d mean that instance would receive all the requests.
To have a more balanced deployment, what we do is to run an haproxy on all of the nodes, health checking and reverse proxying all instances. So now requests will first be received by the haproxy running on the govip leader. Now is the time where you say “Wouldn’t this fail if haproxy is gone, just like the instance could in the previous paragraph?”. Yes, it would. For that purpose we wire haproxy and govip together using systemd requires/wants relations. And of course it can be improved but it showed a lot of potential surviving some weird cases in the last year.
It’s a pretty simple piece of code and it’s open-source. Fork it already!

