
Call it data science, big data, data engineering, or just a plain SQL database, one of the constant things is that all need a way to ingest the data. Without the data itself, none of the differences between those concepts matter much. Another constant is that the systems we rely on will fail at some point. In this post we focus on how we try to design the structure for a streaming data project where we could receive data somewhat reliably.
We use Kafka pretty much for everything and that starts at the beginning: all the data we receive needs to be sent to Kafka. It already has some guarantees so it will be possible for us to tune them when necessary. Thanks to recent client libraries, sending data to kafka is far easier than what it was a few years ago. Still, we need some pre-processing like filtering junk data beforehand so our data flow looks like this:
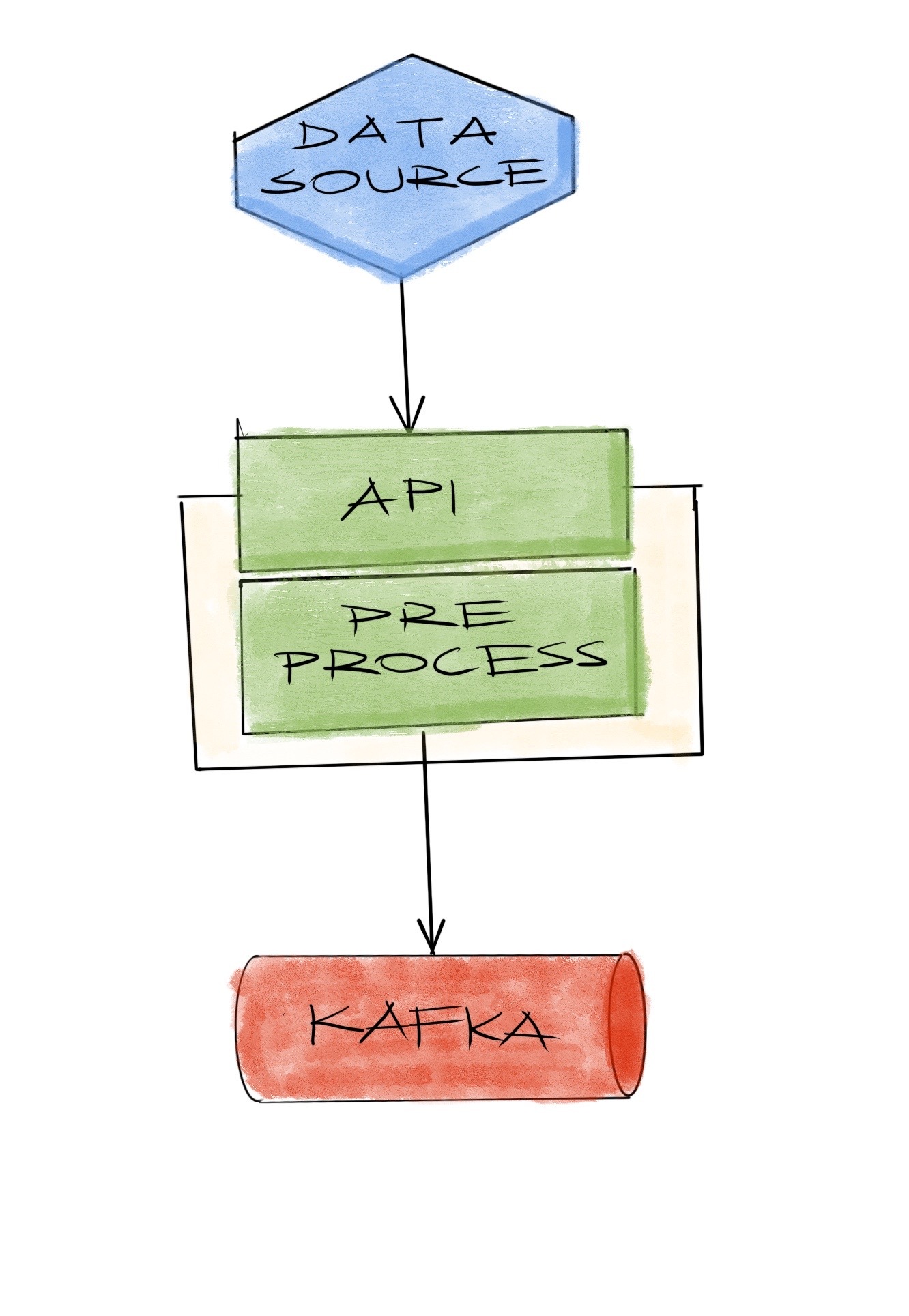
This is one of the simplest solutions to the first problem of ingesting data we just described. Second problem being any system failure, we design for that in the next step.
Going from top to bottom; when the data source fails, there isn’t much to do on the receiving end since it wouldn’t receive anything. I guess we could design a data collection system that will corrupt everything when some source stops sending data but it would be hard,… and pretty much pointless.
When the networking or the API fails the source will have some data but it won’t be able to send them, so it’ll have two options: drop them, or buffer them and wait for the API to come back. Our requirement is both actually: buffer for intermittent failures and drop when a buffer limit has been reached.
When pre-processing fails the source will be able to connect and send data to API but they will still be lost since they won’t reach Kafka. At that point we have again two options: Drop or retry pre-processing until it succeeds.
When the next piece of networking or Kafka fails it will be similar to the previous failure, where the source has sent the data but the system is unable to store them reliably. By the way, again, we assume kafka is storing them reliably and not interested in its intricacies at this moment.
Since the data source will have to design a buffer and drop mechanism for the API failures anyway, it makes sense to reuse it instead of designing different modes for different types of failures. API could return whether the data was stored in Kafka and source can check that return value to retry sending when something fails. With that idea in mind, we start the implementation.
API is a gRPC service so it looking like this:
message Data {
// payload
// metadata
}
message DataReceived {
}
service myAPI {
rpc send(stream Data) returns (stream DataReceived);
}
Server will read the data from client, filter pre-process as necessary, and send it to kafka, and return a result only when it receives the confirmation from kafka. Unsurprisingly KafkaSender in reactor-kafka has just the API we need:
<T> Flux<SenderResult<T>> send(
Publisher<? extends SenderRecord<K,V,T>> records)
In plain terms you send a SenderRecord and receive a SenderResult. You know
sending failed if you didn’t receive anything, an exception was thrown, or the
result received is erroneous. We wire these to complete the middle part of the
collection chain in Java.
public Flux<DataReceived> send(Flux<Data> request) {
return request.flatMapSequential(data -> {
if (preprocess(data)) {
var senderRecord = SenderRecord.create(
new ProducerRecord<String, Data>(topic, data), null);
return sender
.send(Mono.just(senderRecord))
.map(senderResult -> {
// Check for errors
return DataReceived.newBuilder().build();
});
} else {
// Data failed to pass pre-processing
// But we still need to tell we received it
return Flux.just(DataReceived.newBuilder().build());
}
});
}
Data source on the top is a .NET application coded in C#. Microsoft has an
article
showing a way to use gRPC clients as IObservable objects and integrate them in
reactive APIs of .NET. By adding Rx.NET
into the mix we thought we could have the buffer-and-drop mechanism in no time.
That was only partly true. We managed to get it up and running in no time OK,
but it didn’t work.
The first problem was the fact that the Observer.OnNext was being called
concurrently for all data received. That means a naive implementation of trying
to send data to gRPC endpoint will fail, because while it is possible to send
multiple requests in a streaming gRPC call without waiting for the result, it’s
not possible to send more than one request at the same time.
One solution was to provide a lock for the write side - and another for the read
side because of the same limitation. An alternative is using a
.Select(IObservable) followed by a .Merge(1) - as mentioned
here.
Both solved the concurrent sending problem but came up short for the second one
though: the client just kept sending data, even when the API wasn’t able to
return anything. There’s just no way to signal the client to slow down or just
stop sending. Or we weren’t able to find it anyway. This is generally handled by
the built-in back-pressure stuff and after finding out rx.net doesn’t have
anything out of the box unlike
RxJava or some
others, we had -again- two options: try to force-place it ourselves, or go look
for something else.
It always helps to look around a little bit before doing something on your own. Even if you’d have to do it in the end, you’d have gained a lot of context you don’t have in the first place. So again we went for the second option to find out about TPL data-flow. It’s goals are similar to Rx but the API is a bit different. Rx is integrated and works best with linq statements while TPL data-flow provides an actor-like framework. In short it’s not very shiny and definitely not as popular.
But it has what we need in two basic structures. A BufferBlock acts like a
blocking queue with limited capacity to solve our buffer-and-drop requirement.
An ActionBlock on the other hand provides an asynchronous way to handle and send
the data over the network.
// This will buffer up to 10000 objects
var dataQueue = new BufferBlock<Data>(
new DataflowBlockOptions { BoundedCapacity = 10000 });
// This will send them one-by-one
var sender = new ActionBlock<Data>(async data => {
await grpcCall.RequestStream.WriteAsync(data);
await grpcCall.ResponseStream.MoveNext();
var response = grpcCall.ResponseStream.Current;
// validate response, handle errors and retry
}, new ExecutionDataflowBlockOptions {
MaxDegreeOfParallelism = 1,
BoundedCapacity = 1
});
// Wire them
var disposable = dataQueue.LinkTo(sender);
// Application will try to send data like
while (!dataQueue.Post(e)) {
// But buffer is full, drop from queue
dataQueue.Receive();
}
Final solution will also need to have error handling but that’s pretty easy with a standard try-catch block. Semantics aside, this is what we’d basically expect from a back-pressure handler. Client is unable to send data to the server for some reason, so it will wait while buffering whatever it wants to send. There are other generic backpressure behaviours but they’re up to your imagination after this point.
Small caveat here is that the ActionBlock has a buffer too. We specified it as
1 to allow only one “in-flight” request. So every data sending request will
have to wait for the previous one to complete. If the previous request isn’t
complete, this client will never send another one. In practice, only 1 inflight
request will work with a very low throughput, but it would be pretty easy to
increase it if we need to increase it.
To sum it up, the data collector structure here will tolerate the interesting scenario of a kafka failure, where the Java coded server side won’t be able to write anything to Kafka, but it won’t be a problem because the C# coded client side will stop sending more. Happy hacking!
P.S. If your environment is not insane like ours, as in you can use RxJava on both sides, you’re in luck. reactive-grpc has everything you need already.

