
Durability is what separates a data storage system from simply using an external hard drive, a USB stick or a smartphone. When one of those simpler storage solutions fails, it’s safe to say that the data is toast. When we don’t want the data to be toast when things drop out of our pockets, we back them up to a more secure place like “the cloud”. We do that because we cannot reliably stop things falling out of our pockets no matter what we do.
Similar failures happen in data storage systems - and in “the cloud”, too. And similarly they have to back the data up continuously to ensure that nothing is lost after an unexpected outage. This is called mirroring or replication depending on the infrastructure. While the techniques are a bit different, the logic is the same: Keep copies of the data on other systems/components so when a copy fails, the data is no longer toast, it’s safe somewhere else. Simple enough.
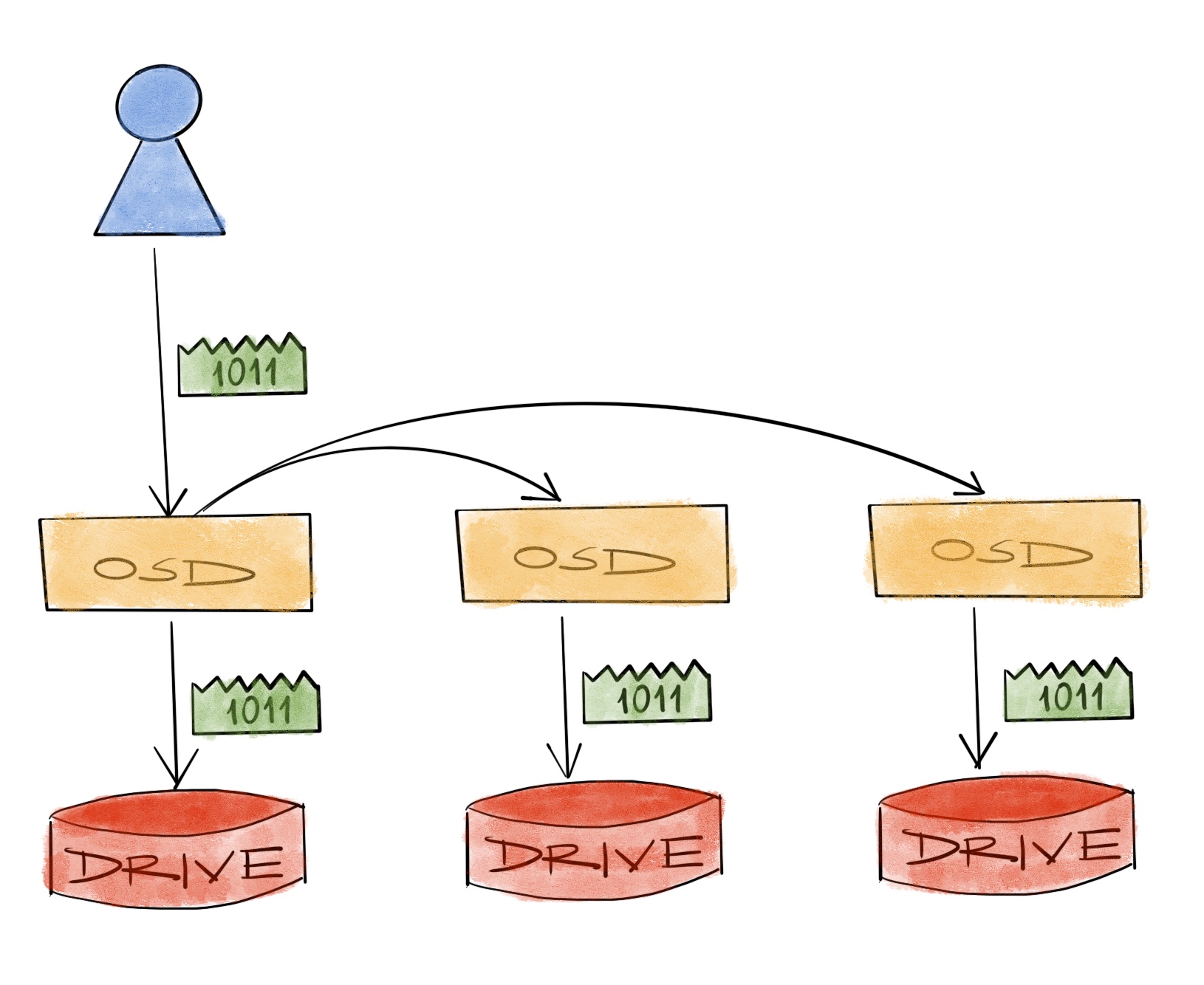
But for some amount of data this approach of keeping copies around is simply not feasible. After some number of drives/components, the number of copies you have to keep around also increases and costs multiply. When a size problem becomes a cost problem, an interesting yet straightforward course of action is to introduce - or increase the level of, complexity. In practice this means, it may be possible to have the same level of durability with fewer number of copies, if we’re willing to make some complex computations. Enter erasure codes.
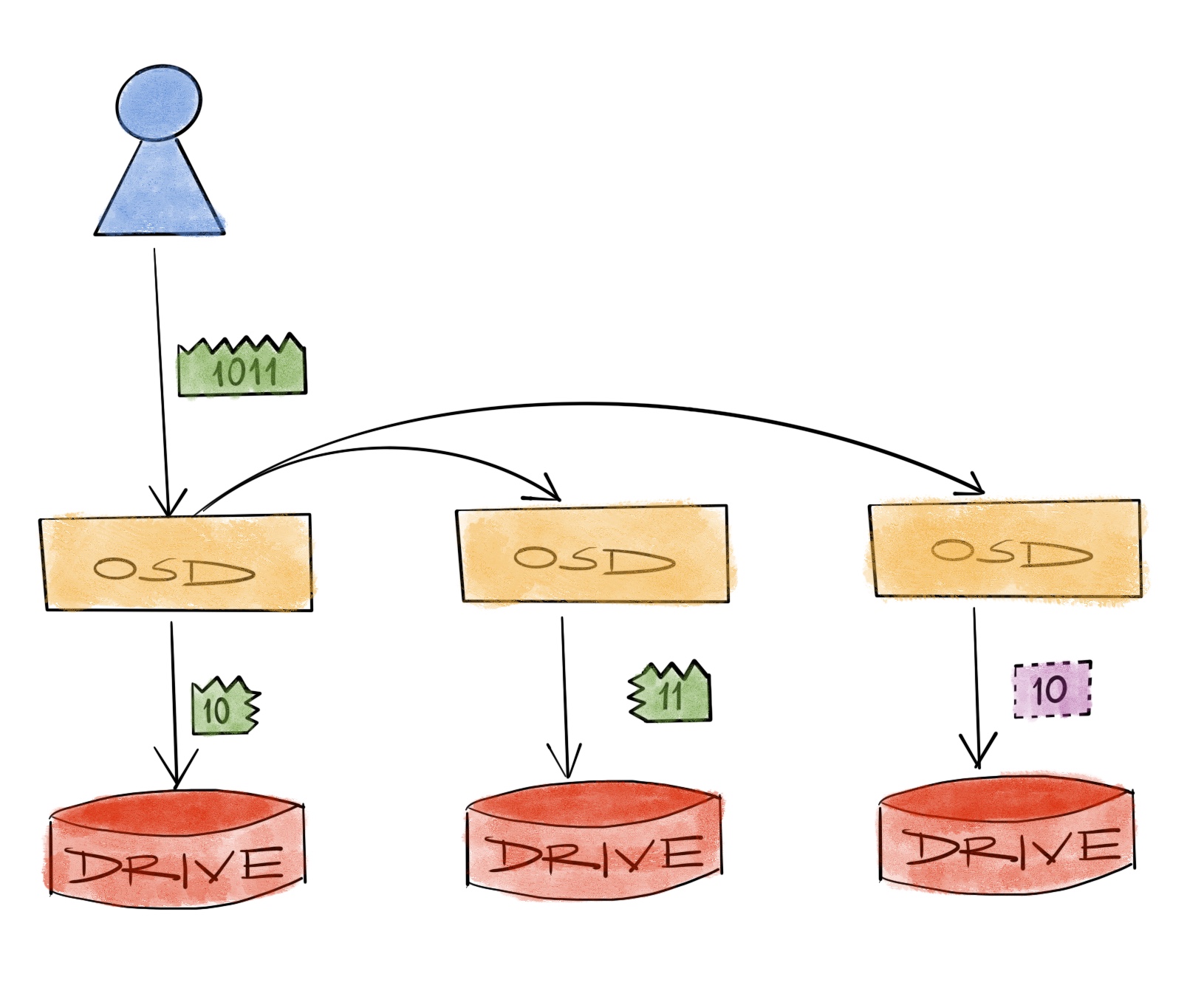
In this rather simple example, we’ve decreased the total capacity requirement by 50% just by adding the complexity of calculating some XOR’s. But in order to truly appreciate the total cost, we need to account for something else: the recovery, or in other words, how to reach a stable state after a component fails. The recovery is the very thing these systems are preparing for, yet it almost always becomes an afterthought. The conversations usually get stuck in the benefits of capacity efficiency or some irrelevant performance goals before reaching the point where the system’s reaction to a replaced drive is discussed.
In the previous replication example where one component fails and is replaced, the system has to
- Read from a copy
- Transfer that to target
- Write it to replaced component
But for the XOR example, it has to
- Read from all of the remaining components
- Transfer all of them to one location
- Re-calculate XOR
- Transfer result to target
- Write it to replaced component
As we can see here while we initially thought we’d only have some calculation costs, our logistics costs have multiplied as well. All of this might be happening within a RAID controller and you might not care but it’s still a cost you need to be aware of at least in the sense of time it will take to fully recover. If it’s a distributed storage system, it’s easier to be aware of that because logistics is handled by a 3rd party named networking, and you literally pay by the meter.
Just like the previous example, this is another topic where increasing numbers work against us. After some number of nodes, it isn’t feasible to increase the logistics budget by throwing more networking equipment to the problem of recovery, especially because of the diminishing returns. It’s like adding more lanes to reduce traffic. It makes sense when you think about it, and it definitely helps low traffic roads, but it doesn’t work beyond some number of vehicles.

And again the solution is to increase the level of complexity.
Ceph, fortunately supports all of those above and more. It’s possible to pick the appropriate level of complexity required by the numbers in the solution. In the roughest sense, if the total amount of data will fit on a few dozen drives, it might make sense to replicate them all to have maybe a hundred drives total. If it’s a few hundred, default erasure codes will definitely help keeping the final number still in the hundreds. If it’s in the thousands, well, … it pays to test possible alternatives. Ceph has several so that we can test and pick the most appropriate one.
We’ll go into an example scenario and test it using different techniques in the next post.

